Methods
We applied an upstream stakeholder engagement method which involves eliciting responses from domain experts prior to implementing a model or system.
We used an intentional sampling approach to recruit participants for interviews, aiming to recruit experts with diverse levels of experiences in medical systematic review production (from methodologists, practitioners, clinical researchers, editors, and publishers working in research synthesis, to clinical guideline experts who make use of such reviews).
We conducted a qualitative study because we are interested in characterizing the general views on LLMs of domain experts, and surveys would have artificially constrained responses. We developed an interview guide based on our research questions. During the interviews, we shared with participants (domain experts) samples of typical outputs from LLMs that were prompted to generate evidence summaries based on a medical query to act as probes to spark discussion. Figure 1 shows a schematic of our study in 5 steps.
For this exploratory study, we used the following generative LLMs: Galactica 6.7B, BioMedLM 2.7B, and ChatGPT (February 13 and March 23 versions). These LLMs were chosen for the study as they are able to generate biomedical and clinical text.
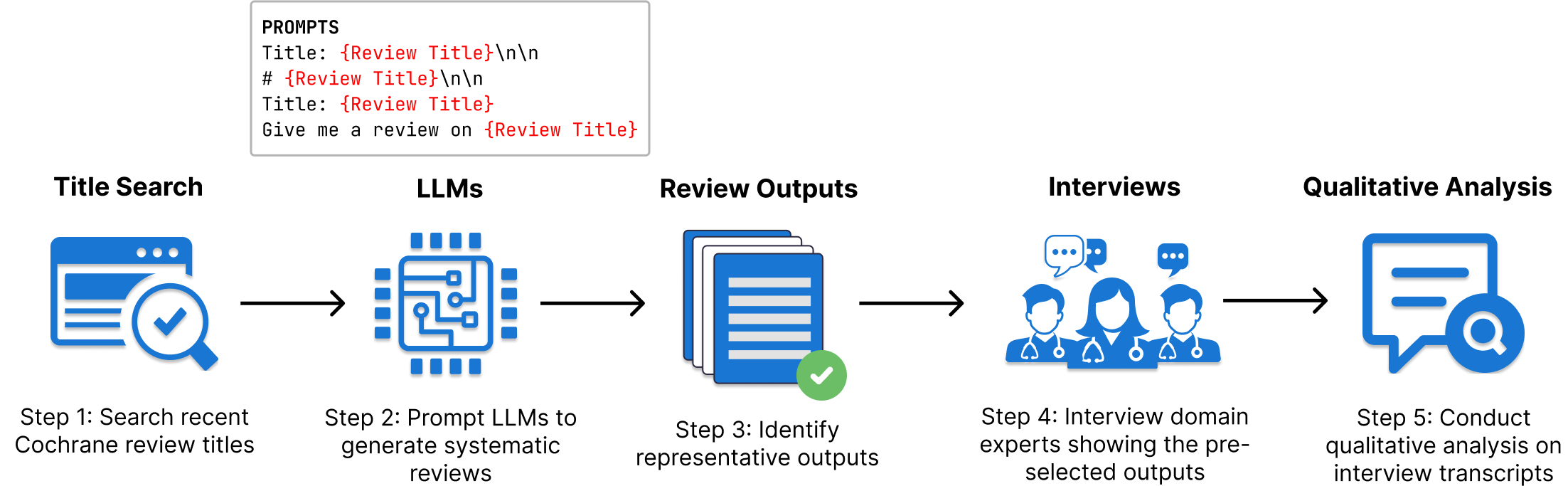 |
| Figure 1 - A schematic of our study, in 5 steps. In Step 1, we conducted a search of recently published medical systematic reviews from an evidence synthesis database named Cochrane. Step 2 involved using the titles from Step 1 to prompt the LLMs to generate evidence summaries. Step 3 involved sampling outputs generated from Step 2. Step 4 entailed interviewing domain experts. Finally, Step 5 involved conducting the qualitative analysis of the interview transcripts. |
We used very open-ended prompts to generate the evidence summaries so that we can get an illustration of the nature of current large language models and what they are capable of. We only used the titles of the Cochrane reviews as part of the prompts. Figure 2 provides the prompts we used for this project. The task of asking the models to generate synthesis reviews allows us to explore the nature of large language models because we have the genuine human-written reviews.
 |
| Figure 2 - Prompts used for generating the evidence summaries. Only the titles of real Cochrane review were provided to the models so that we can get an illustration of the nature of current large language models and what they are capable of. |
The code and full list of the medical topics and titles used to generate the evidence summaries with LLMs are available in our Github repository. The Github repository will be made available in the near future.
After generating a set of outputs, we conducted a rapid inductive qualitative analysis to identify error categories and other properties deemed salient by domain experts. We identified 11 general concepts characterizing model-generated summaries: Incomplete or Short Outputs; Contradictory Statements Within or Compared to Ground Truth; Numerical Values; Undesirable Outputs; Citations and References; Agreement with Ground Truth; Time; Proper Names and Personally Identifiable Information; Unimportant Additional Information; Repetition; and Text for Visuals (Figures and Tables).
We manually identified 6 samples of outputs that featured many of the characteristics identified during the analysis process. We decided to select a subset of typical outputs to reduce the area of exploration to ground our exploratory study to focus on potential benefits and risks.
The 6 samples of outputs are available in the following pages:
Generating Evidence Summaries Directly Aligned with Individual Expertise
Given the range of clinical topics we considered, individual participants may have little familiarity with the subject matter in the random samples (Step 3) presented to them. To ensure that participants were shown at least one output related to a topic they were intimately familiar, we asked them to provide the title of a medical systematic review that they had recently worked on prior to each interview. Using each participant’s provided title, we generated a personally-aligned output.
All the summaries directly aligend with individual expertise of our participants are available in the additional examples page.